OpenCitations and its Corpus
The OpenCitations Project (http://opencitations.net) is creating an open dataset of citation data integrated with a SPARQL endpoint and a very simple Web interface that shows only the data about bibliographic entities1. Its main output is the Open Citations Corpus (OCC), an open repository of scholarly citation data made available under a Creative Commons CC0 license, which provides accurate bibliographic references harvested from the scholarly literature, described using the SPAR Ontologies [5] according to the OCC metadata document [3], that others may freely build upon, enhance and reuse for any purpose, without restriction under copyright or database law.
The OCC stores metadata relevant to these citations in RDF, encoded as JSON-LD, and makes them available through a SPARQL endpoint (and, in the near future, as downloadable datasets). It includes information about six different kinds of bibliographic entity:
-
bibliographic resources (br) – resources that cite/are cited by other bibliographic resources (e.g. journal articles), or that contain such citing/cited resources (e.g. journals);
-
resource embodiments (re) – details of the physical or digital forms in which the bibliographic resources are made available by their publishers;
-
bibliographic entries (be) – the literal textual bibliographic entries occurring in the reference lists within bibliographic resources, that reference other bibliographic resources;
-
responsible agents (ra) – names of agents having certain roles with respect to bibliographic resources (i.e. names of authors, editors, publishers, etc.);
-
agent roles (ar) – roles held by agents with respect to bibliographic resources (e.g. author, editor, publisher);
-
identifiers (id) – external identifiers (e.g. DOI, ORCID, PubMedID) associated with the bibliographic entities.
The corpus URL (https://w3id.org/oc/corpus/) identifies the entire OCC, which is composed of several sub-datasets, one for each of the aforementioned bibliographic entities included in the corpus. Each of these has a URL composed by suffixing the corpus URL with the two-letter short name for the class of entity (e.g. be
for a bibliographic entry) followed by an oblique slash (e.g. https://w3id.org/oc/corpus/be/). Each dataset is described appropriately by means of the Data Catalog Vocabulary and the VoID Vocabulary.
Upon initial curation into the OCC, a URL is assigned to each entity within each sub-dataset, all of which can be accessed in different formats (HTML, RDF/XML, Turtle, and JSON-LD) via content negotiation. Each entity URL is composed by suffixing the sub-dataset URL with a number assigned to each resource, unique among resources of the same type, which increments for each new entry in that resource class. For instance, the resource https://w3id.org/oc/corpus/be/537 is the 537th bibliographic entry recorded within the OCC. Each of these entities has associated metadata describing its provenance by means of PROV-O and its PROV-DC extension (e.g. https://w3id.org/oc/corpus/be/537/prov/se/1). In particular, we keep track of the curatorial activities related to each OCC entity, the curatorial agents involved, and their roles. Additional information about OCC's handling of citation the data, and the way they are represented in RDF, are detailed in the official OCC Metadata Document [3].
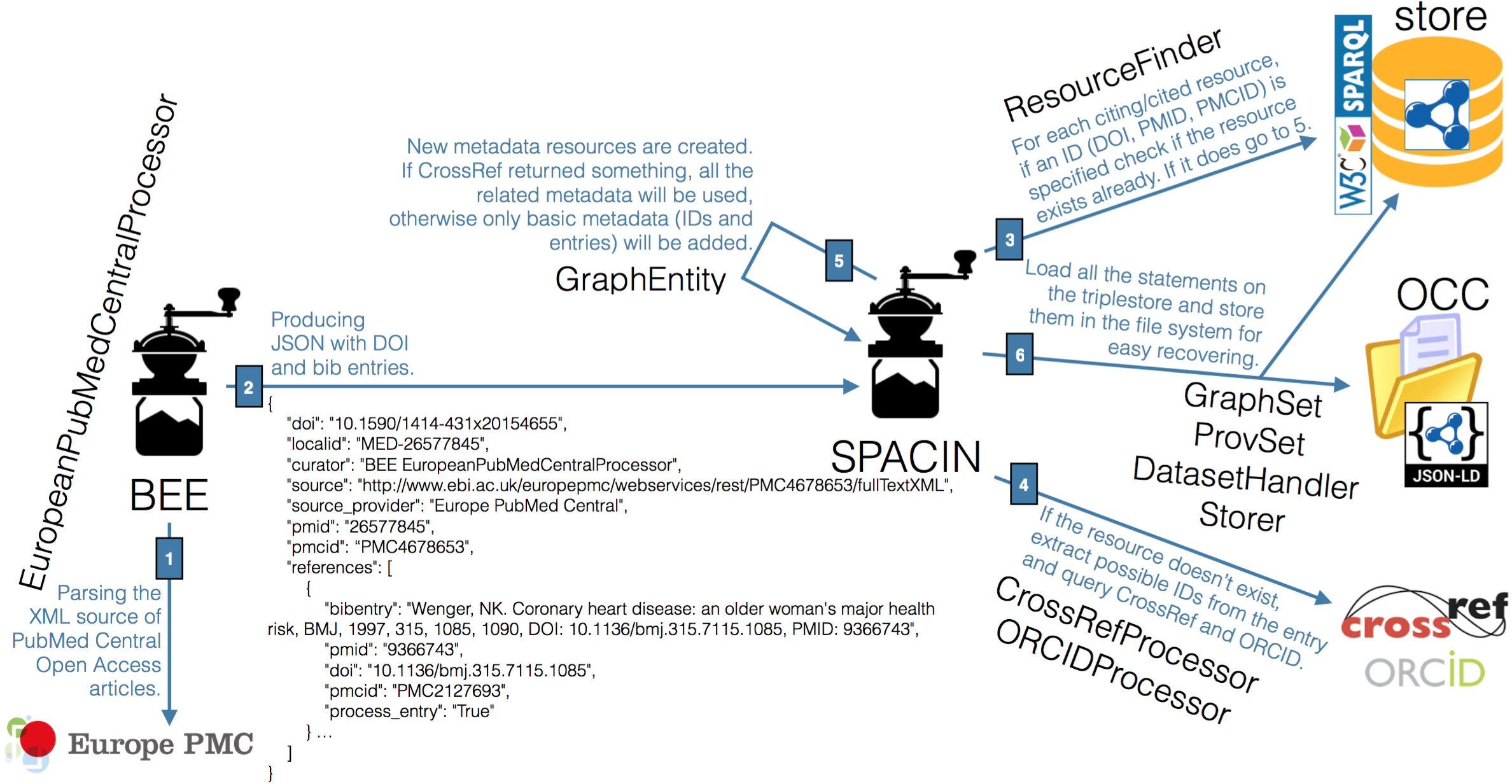
The ingestion of citation data into the OCC is handled by two Python scripts called Bibliographic Entries Extractor (BEE) and the SPAR Citation Indexer (SPACIN), available in the OCC's GitHub repository. As shown Figure 1, BEE is responsible for the creation of JSON files containing information about the XML articles in the OA subset of PubMed Central (retrieved by using the Europe PubMed Central API and used as input data). Each of these JSON files also includes the complete reference list of the paper under consideration extracted by means of XPath queries. Then, SPACIN processes each JSON file, retrieves metadata information about all the citing/cited articles described in it by querying the Crossref API and the ORCID API, and stores all the generated RDF resources in the file system in JSON-LD format and within the OCC triplestore, disambiguating the resources that have been added previously by means of the retrieved identifiers (i.e. DOI, PMID, PMCID, ORCID, URL). It is worth noting that the triplestore includes all the data about the curated entities except their provenance data and the descriptions of the datasets, that are accessible only via HTTP.
The workflow introduced in Figure 1 is a process that runs until no more JSON files can be produced by BEE. Thus, the current instance of the OCC is evolving dynamically in time, and can be easily extended so as to interact with additional REST APIs from different sources, so as to gather additional article metadata and their related references. Currently, each day the workflow adds about 2 million triples to the corpus, describing more than 20,000 new citing/cited bibliographic resources and about 100,000 new authors, about 5% of whom are disambiguated through their ORCID ids.